
光回線を提供しているプロバイダを調査するために、「みんなのネット回線速度」から、Python言語でBeautifulSoupによるスクレイピングにより、プロバイダ名、通信速度、通信環境等の情報を取得しました。
今回作成するアプリを次に示します。
- 1.スクレイピングアプリ「scraping.py」
- 上記で取得したURLを用いて次に示す範囲の情報を取得しファイル化します。
- 次のコマンドでスクレイピングアプリ「scraping.py」を実行します。
- 2.要約アプリ「summary.py」
- 収集した情報を用いてプロバイダごとの登録数をカウントしてファイル化します。
次のコマンドで要約アプリ「summary.py」を実行します。 - 3.解析アプリ「analize.py」
- 収集した情報を用いてプロバイダごとに通信環境と通信速度を取得してファイル化します。
次のコマンドで解析アプリ「analize.py」を実行します。

>py.exe scraping.py まちさん 神奈川県横浜市西区 2020年08月11日(火) 22時01分回線タイプ: 光回線 プロバイダ: So-net 住宅の種類: 集合住宅(マンション・アパート) ネット接続方法: 無線(Wifi)端末の種類: 携帯電話(スマートフォン) OS名: ios ブラウザ: Mobile Safari ジッター値: 65.79ms Ping値: 8.0ms ダウンロード速度: 80.28Mbps アップロード速度: 215.31Mbps みんそく291956さん 神奈川県横浜市西区 2020年08月11日(火) 19時40分回線タイプ: 光回線 プロバイダ: GMOとくとくBB 住宅の種類: 集合住宅(マンション・アパート) ネット接続方法: 有線端末の種類: デスクトップPC OS名: windows ブラウザ: Chrome IPv4接続方式: IPoE + IPv4 over IPv6(v6プラス)IPv6接続方式: IPoE(v6プラス) 【IPv4接続】ジッター値: 0.57ms Ping値: 6.8ms ダウンロード速度: 642.49Mbps アップロード速度: 552.26Mbps【IPv6接続】ジッター値: 0.53ms Ping値: 6.61ms ダウンロード速度: 699.68Mbps アップロード速度: 512.21Mbps ・・・ ・・・
>py.exe summary.py So-net count:52 GMOとくとくBB count:7 楽天ブロードバンド count:10 Fiber Bit count:7 @nifty count:41 ・・・ ・・・
>py.exe analize.py 3 GMOとくとくBB 有線 PC windows 【IPv4】down: 642.49Mbps up: 552.26Mbps【IPv6】down: 699.68Mbps up: 512.21Mbps 5 GMOとくとくBB 有線 PC windows 【IPv4】down: 191.67Mbps up: 460.99Mbps【IPv6】down: 200.26Mbps up: 0.94Mbps 43 GMOとくとくBB 無線 PC windows 【IPv4】down: 53.02Mbps up: 38.31Mbps【IPv6】down: 52.3Mbps up: 38.55Mbps ・・・ ・・・
スクレイピングを行うURLの取得
スクレイピングする「みんなのネット回線速度」のURLを次の手順で取得します。
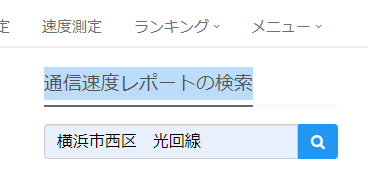
- 右側のメニューにある「通信速度レポートの検索」に「横浜市西区 光回線」を設定して検索します。
- 検索結果を表示させると下にスクロールさせると次のような戸建て・集合住宅の選択が可能となるので、集合住宅を選択します。
- 表示された検索結果のURL「https://minsoku.net/speeds/optical/prefectures/14/areas/141038/house_types/condominium?page=2」を取得します。

スクレイピングアプリ「scraping.py」の作成
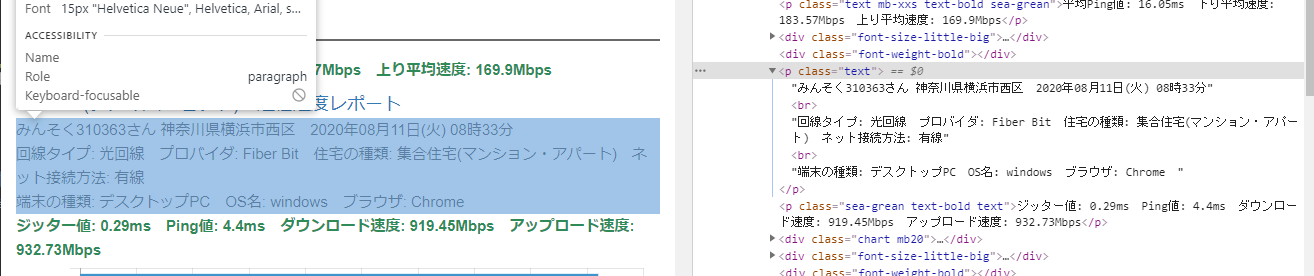
取得したURLからスクレイピングした通信情報をスクレイピングファイル「西-scraping」に保存します。対象とするページをChrome デベロッパーツールのElementsパネルで表すると次のようになっており、BeautifulSoupを使って、「’p’, class_=’text’)」をパラメータにしてfind_allメソッドで切り出します。
import urllib.request
import sys
from bs4 import BeautifulSoup
area = "西-"
f = open(area + "scraping", mode='w')
for page in range(160):
url = "https://minsoku.net/speeds/optical/prefectures/14/areas/141038/house_types/condominium?page=" + str(page+1) #西区
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0"
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
soup = BeautifulSoup(response, 'html.parser')
for tag in soup.find_all('p', class_='text'):
if '※' in tag.text: break
if '平均Ping値' in tag.text: continue
print(tag.text)
f.write(tag.text + "\n")
f.close()
14行目でurlopenメソッドを実行すると、次のエラーメッセージが表示される場合があります。
urllib.error.HTTPError: HTTP Error 403: Forbidden
これは、http 403. 閲覧権限がないためです。11行目のようにRequestでユーザーエージェントをfirefoxに偽造することで回避できます。
要約アプリ「summary.py」の作成
スクレイピングファイル「西-scraping」を用いて、要約した結果を要約ファイル「西-summary」に保存します。class「Provider」はプロバイダ名と 登録数を変数で持ち、スクレイピングファイル「西-scraping」を用いて、すでに登録されていれば登録数をカウントアップし、登録されていなければプロバイダ名を登録します。作成したプロバイダ名と登録数はリスト「Provider_info」に保存され、登録終了後に要約ファイル「西-summary」に保存します。
#!/usr/bin/python
# coding: UTF-8
import re
class Provider:
def __init__(self, name):
self.name = name
self.count = 1
area = "西-"
fw = open(area + "summary", mode='w')
f = open(area + 'scraping')
lines2 = f.readlines() # 1行毎にファイル終端まで全て読む(改行文字も含まれる)
f.close()
Provider_info = []
for line in lines2:
if 'プロバイダ:' in line:
m = re.search('プロバイダ:(.*)住宅の', line)
provider = m.group(1)
findflg = False
for member in Provider_info:
if provider == member.name:
member.count += 1
findflg = True
break
if not findflg:
Provider_info.append(Provider(provider))
for member in Provider_info:
print("{} count:{}".format(member.name, member.count))
fw.write("{} count:{}\n".format(member.name, member.count))
fw.close()
解析アプリ「analize.py」の作成
スクレイピングファイル「西-scraping」を用いて、解析した結果を解析ファイル「西-GMOとくとくBB」に保存します。解析では利用者の通信環境と実際の通信速度の2種類の情報を組み合わせて一行に表示します。
- 22-36行目で通信環境、39-56行目で通信速度の処理を行います。
- 2種類の情報がそろっているかをチェック、は、23行目と40行目で行い、エラーを検出した場合は処理を終了します。エラーを検出した場合は、スクレイピングファイル「西-scraping」をエディタ等で編集します。
- 55行目でファイル化したいプロバイダの名称をチェックします。
#!/usr/bin/python
# coding: UTF-8
import re
area = "西-"
fw = open(area + "GMOとくとくBB", mode='w')
f = open(area + 'scraping' )
lines2 = f.readlines() # 1行毎にファイル終端まで全て読む(改行文字も含まれる)
f.close()
# lines2: リスト。要素は1行の文字列データ
num = 0
data1 = 0
data2 = 0
provider = ""
os = ""
for line in lines2:
num += 1
if 'プロバイダ:' in line:
if num != (data1 + 1):
print("プロバイダデータエラー!\n")
print(str(num) + " " + line + "\n"),
break
data1 = num + 1
m = re.search('プロバイダ:(.*)住宅の', line)
provider = m.group(1)
m = re.search('ネット接続方法: (.*)ブラ', line)
os = m.group(1)
os = re.sub('端末の種類:', "", os)
os = re.sub('OS名: ', "", os)
os = re.sub('デスクトップ', "", os)
os = re.sub('\(スマートフォン\)', "", os)
os = re.sub('\(Wifi\)', "", os)
if 'ダウンロード速度:' in line:
if num != (data2 + 2):
print("ダウンロード速度エラー!\n")
print(str(num) + " " + line + "\n"),
break
data2 = num
m = re.search('ダウンロード速度:(.*)【IPv6接続】', line)
line = re.sub('ジッター値:.*?ms ', "", line)
line = re.sub('Ping値:.*?ms ', "", line)
line = re.sub('ジッター値:.*?ms ', "", line)
line = re.sub('Ping値:.*?ms ', "", line)
line = re.sub('接続', "", line)
line = re.sub('ダウンロード速度', "down", line)
line = re.sub('アップロード速度', "up", line)
print(str(data1 - 1) + " " + provider + line)
if 'GMOとくとくBB' in provider:
fw.write(str(data1 - 1) + " " + provider + " " + os + line)
print
fw.close()